新网站做优化要准备什么南阳seo
目录
引言
Fine-tuning技术的原理阐
预训练模型
迁移学习
模型初始化
模型微调
超参数调整
任务设计
数学模型公式
Dify平台介绍
Dify部署
创建AI
接入大模型api
选择知识库

个人主页链接:东洛的克莱斯韦克-CSDN博客
引言
Fine-tuning技术允许用户根据特定任务的需求对预训练好的大模型进行微调,从而提高模型在特定任务上的性能。相比从头开始训练模型,可以显著降低训练成本和时间。还可以快速适应新任务的数据分布和特征,使模型能够更好地适应新的应用场景。
Dify平台提供了丰富的预训练模型和自定义模型,用户可以直接在平台上进行Fine-tuning,无需自行准备和训练模型。该平台提供了数据导入、清洗、标注等丰富的数据处理功能,用户可以方便地对数据进行预处理和后处理,为Fine-tuning提供高质量的数据支持,从而进一步降低了成本。通过在Dify平台上应用Fine-tuning技术,用户可以轻松地对模型进行调整和优化,从而显著提升模型在新任务上的准确率、召回率等性能指标。

Dify平台支持多种主流的机器学习和深度学习框架,如TensorFlow、PyTorch等,方便用户进行开发和部署。平台提供了自动化部署工具,用户只需简单配置即可将模型部署到云端或本地服务器上,降低了部署的难度和时间成本。
Fine-tuning技术的原理阐
预训练模型
预训练模型是在大量无标注或标注数据上预先训练的深度学习模型,如BERT、GPT等。这些模型通过在大规模文本数据上进行无监督学习,已经学习到了丰富的语言特征、词汇、语法和语义知识。
迁移学习
Fine-tuning是迁移学习的一种具体应用。迁移学习的核心思想是利用在一个任务上学习到的知识来帮助解决另一个不同但相关的任务。在Fine-tuning中,我们将预训练模型的知识迁移到新的特定任务上。
模型初始化
在Fine-tuning过程中,我们首先使用预训练模型的参数作为新任务模型的初始参数。这样做的好处是,预训练模型已经学习到了通用的语言特征,这些特征在新任务中仍然是有用的。
模型微调
接下来,我们在新的特定任务的数据集上继续训练模型,对模型的参数进行微调。这通常包括解冻预训练模型的一部分层(通常是高层),并使用新任务的数据和标签进行训练。通过反向传播和梯度下降等优化算法,模型会根据新任务的要求对权重进行更新,从而适应新任务的特定特征。
超参数调整
在Fine-tuning过程中,超参数的调整至关重要。超参数如学习率、批次大小和训练轮次等需要根据特定任务和数据集进行调整,以确保模型在训练过程中的有效性和性能。
任务设计
任务设计是Fine-tuning的关键一步。它决定了模型如何从预训练阶段迁移到特定任务。任务设计需要考虑的因素包括输入输出的形式、损失函数的选择、模型结构的调整等。
例如,对于文本分类任务,可能需要修改预训练模型的输出层以适应新的类别数量;对于序列生成任务,可能需要调整模型的解码器部分。
数学模型公式
Fine-tuning在数学上可以被看作是一个优化问题。假设预训练模型是(f(\cdot;\theta)),其中(\theta)是模型的参数。我们的目标是找到一组参数(\theta^*),使得模型在新任务上的损失函数最小。这通常通过反向传播和梯度下降等优化算法来实现。
如下是基于深度学习框架以及预训练模型库。使用PyTorch和Transformers库进行Fine-tuning的简化代码示例,以文本分类任务为例来帮助大家理解。
import torch
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from transformers import BertTokenizer, BertForSequenceClassification, AdamW, get_linear_schedule_with_warmup
from your_dataset_module import YourDataset # 假设你有一个自定义的数据集类 # 加载预训练模型和分词器
model_name = 'bert-base-uncased'
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name, num_labels=2) # 假设是二分类任务 # 准备数据集
train_dataset = YourDataset(tokenizer, data_file='train.txt', label_list=['0', '1'], max_seq_length=128)
train_sampler = RandomSampler(train_dataset)
train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=16) # Fine-tuning设置
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 优化器和调度器
optimizer = AdamW(model.parameters(), lr=2e-5, eps=1e-8)
epochs = 4
total_steps = len(train_dataloader) * epochs
scheduler = get_linear_schedule_with_warmup(optimizer, num_warmup_steps=0, num_training_steps=total_steps) # 训练循环
for epoch in range(1, epochs+1): model.train() for batch in train_dataloader: b_input_ids = batch['input_ids'].to(device) b_input_mask = batch['attention_mask'].to(device) b_labels = batch['labels'].to(device) optimizer.zero_grad() outputs = model(b_input_ids, attention_mask=b_input_mask, labels=b_labels) loss = outputs.loss loss.backward() optimizer.step() scheduler.step() # 可以在这里添加打印损失或其他监控代码 # 保存模型
model_to_save = model.module if hasattr(model, 'module') else model # 注意:对于DataParallel模型,使用model.module
model_to_save.save_pretrained('./model_save/')
tokenizer.save_pretrained('./model_save/')Dify平台介绍
Dify旨在简化AI应用的创建、部署和管理过程,使开发者能够更快速、更轻松地构建和运营基于GPT等模型的AI应用。
核心功能包括可视化的Prompt编排、运营、数据集管理等,支持开发者通过简单的拖拽和配置,将不同的功能模块组合在一起,快速创建出满足需求的AI应用。
可视化Prompt编排:允许用户通过界面化编写prompt并调试,简化开发过程。
数据集管理:支持多种数据格式,如CSV文件和其他格式的数据,方便用户导入和使用数据。
后端即服务和LLMOps概念集成:涵盖了从数据预处理到模型训练、部署和持续优化的整个流程。
支持多种模型:兼容并支持接入多种大型语言模型,包括OpenAI的GPT系列、Anthropic的Claude系列等。
Dify不仅适用于专业开发者,也允许没有编程基础的用户快速开发和运营自己的AI chatbot应用。
Dify部署
关于Dify部署的问题可参考 LDG_AGI 大佬的文章
主页链接:
LDG_AGI-CSDN博客
文章链接:
AI智能体研发之路-工程篇(二):Dify智能体开发平台一键部署_dify-sandbox-CSDN博客
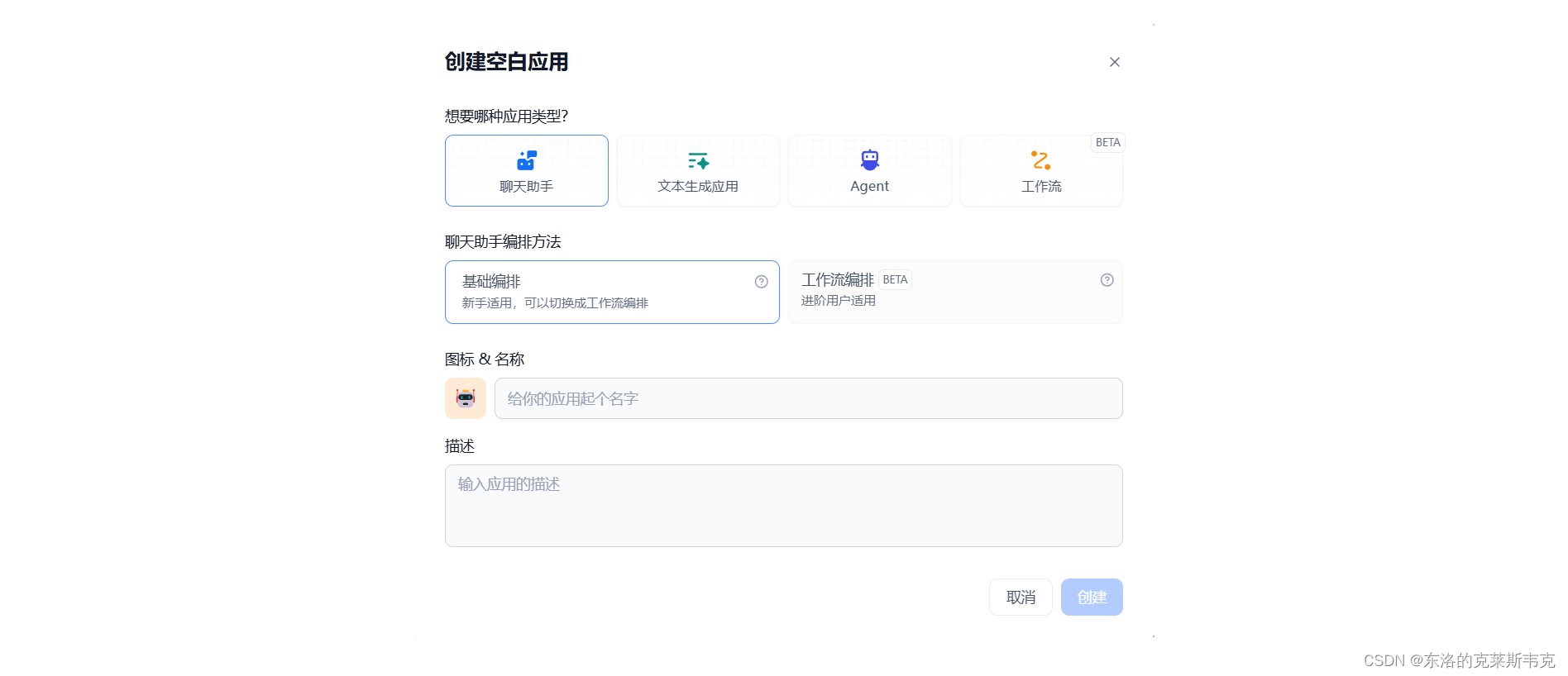
创建AI
新手建议选择基础编排
接入大模型api
首推的就是deepseek,原因很简单——白菜价而且也很稳定

创建api的key

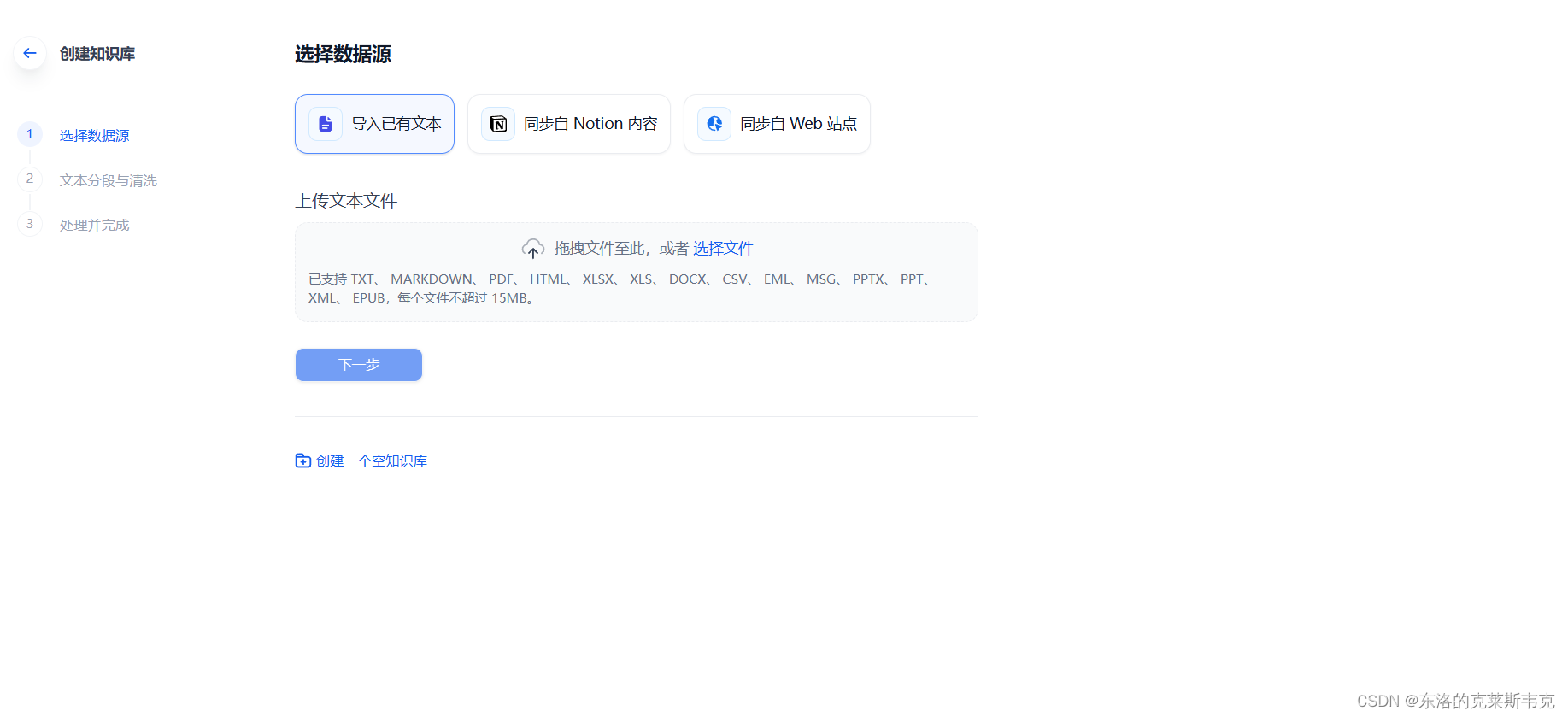
选择知识库
知识库扮演着至关重要的角色,它为用户提供了丰富的数据和信息资源,以支持各种AI应用的构建和运行它包含了各种领域的知识和信息,如文本、图片、音频等,这些数据被用于训练AI模型,为模型提供丰富的背景知识和上下文信息。
以《三国演义》txt文本为例,通过在Dify平台上上传该文本并对模型进行Fine-tuning,模型在回答三国相关问题时能够更加准确和专业