企业网站分为哪三种类型百度如何添加店铺位置信息
目录
一、词向量
1、概述
2、向量表示
二、词向量离散表示
1、one-hot
2、Bag of words
3、TF-IDF表示
4、Bi-gram和N-gram
三、词向量分布式表示
1、Skip-Gram表示
2、CBOW表示
四、RNN
五、Seq2Seq
六、自注意力机制
1、注意力机制和自注意力机制
2、单个输出
3、矩阵计算
4、multi-head self-attention
5、positional encoding
一、词向量
1、概述
在自然语言处理中,用词向量表示一个词,将词映射为向量的形式。
词向量:又叫Word嵌入式自然语言处理中的一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。
2、向量表示
词向量可以有两种表示方法:dispersed representation和distribution representation
dispersed representation:离散表示,一般使用one-hot独热编码。
distribution representation:分布式表示,词嵌入就是分布式表示的形式,可以将一个词通过嵌入空间(embedding)映射为一个定长,稠密且存在语义关系的高维向量,这样可以保证语义接近的词之间的向量相似度较高。
二、词向量离散表示
1、one-hot
one-hot:就是独热编码,将一句话中的每个词都对应一个独热编码,如“我爱学习人工智能”,编码后为:
“我”:[1,0,0,0]
“爱”:[0,1,0,0]
“学习”:[0,0,1,0]
“人工智能”:[0,0,0,1]
独热编码存在问题:缺少词与词之间的关系,由于单词量巨大而产生的维度爆炸和词向量稀疏。
2、Bag of words
将每个单词在语料库中出现的次数加到one-hot编码中。
存在问题:仍没有解决词与词之间关系问题和维度爆炸问题,单词顺序也没有考虑。
3、TF-IDF表示
将罕见的单词加上高权重,常见的加上低权重,其实跟上面一种方法类似。
上述公式中,N为文档总数,表示词t的文档数。
存在问题:同上
4、Bi-gram和N-gram
将两个单词再次组成单词表,或多个单词组成单词表。
存在问题:仍没有解决词义关系问题。
三、词向量分布式表示
一般以Word2Vec作为分布式表示的示例。
Word2Vec:从大量文本中以无监督学习方式训练语义知识的模型,通过学习文本来用词向量的方式表征词的语义信息,也就是在嵌入空间中两个词的空间距离近,则相似度更高。
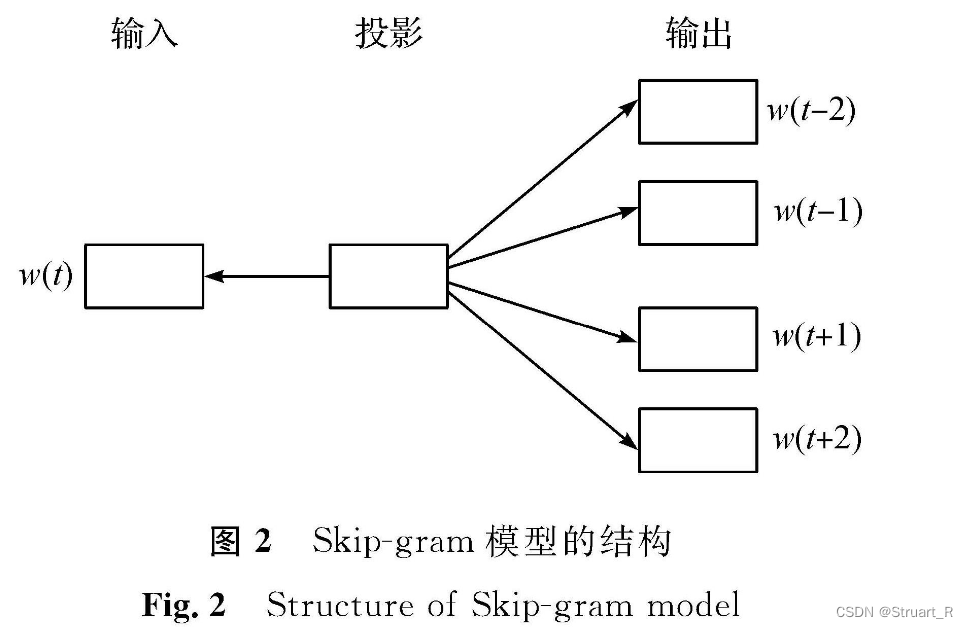
1、Skip-Gram表示
通过中心词预测上下文词,在中心词已知情况下,预测上下文词出现概率
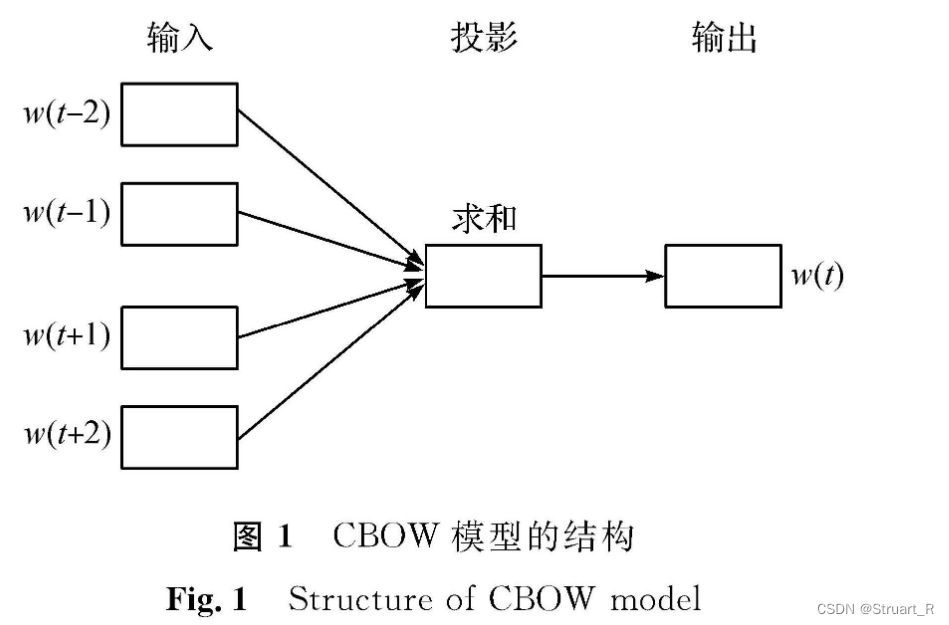
2、CBOW表示
通过上下文词,推理中心词,预测中心词出现的概率。在具体实现中,会使用滑动窗口的方式,读取上下文的词,来计算输出的中心词的极大似然值,训练输出词与真实中心词的相关性,利用梯度下降来进行迭代训练。
四、RNN
RNN:循环神经网络,指在全连接神经网络的基础上增加了前后时序上的关系。RNN的目的是用来处理序列数据,通过在网络中引入循环连接,使得RNN可以记忆之前的信息,并用于当前的输入。
RNN结构:输入层+隐藏层+输出层。RNN结构中的隐藏层,会在每个时间点进行更新,作为网络对序列数据的内部表示,也会收到当前输入和之前隐藏层的影响。
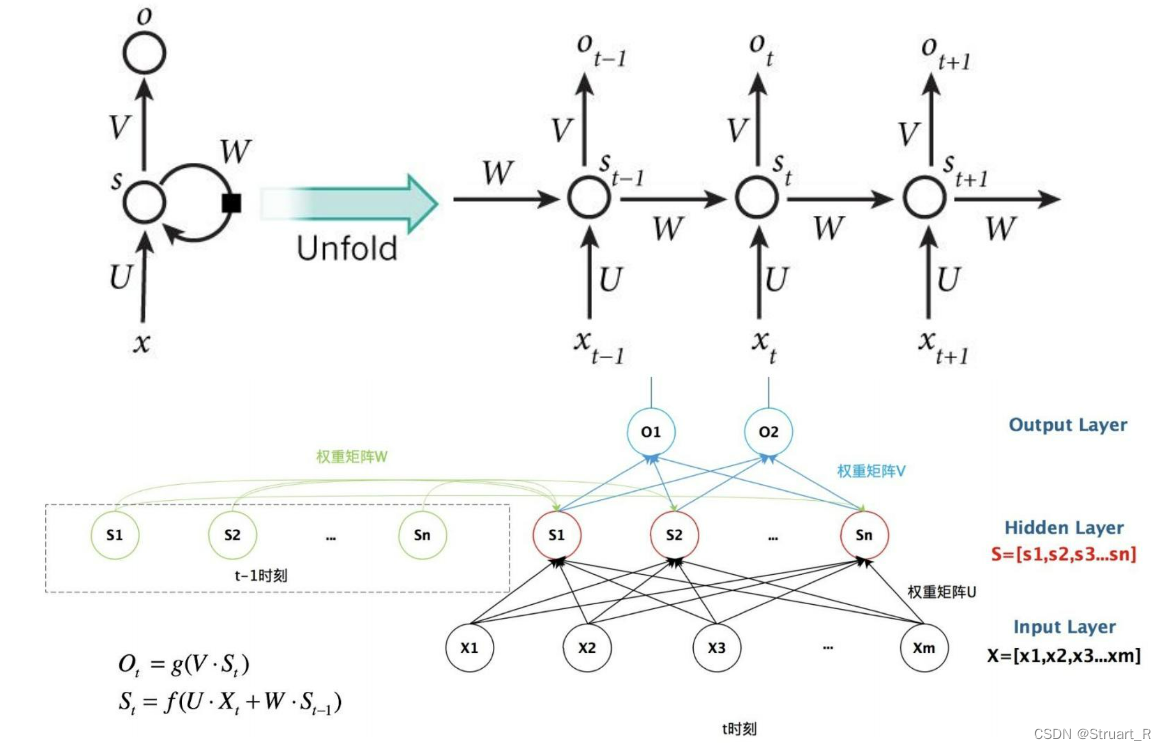
RNN的优点:适用于处理序列数据,具有记忆能力,可以处理变长序列数据。
RNN的缺点:处理长期依赖性问题时,容易产生梯度消失或梯度爆炸问题。由于每个时间点都要进行计算隐藏层和输出,计算效率过低,在长序列数据中会面临资源爆炸问题。
如何解决梯度消失:合理的初始化权重,保证避免梯度消失(有点好笑了),使用ReLU函数作为激活函数,使用LSTM等新型结构。
五、Seq2Seq
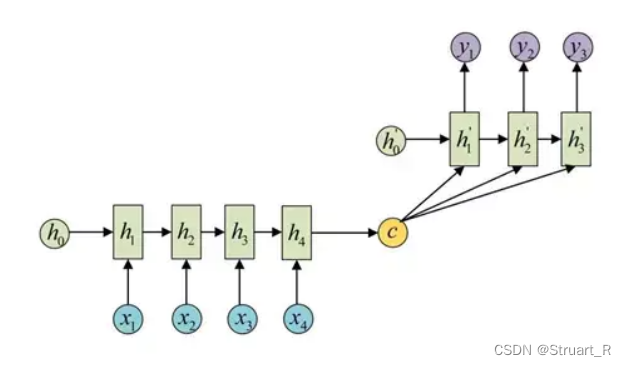
Seq2Seq:序列到序列模型,根据给定的序列,通过特定的生成方法生成另一个序列的方法,这两个序列可以不等长。这种结构又叫做Encoder-Decoder模型(编码-解码模型),也可以称为RNN的一个变种,解决了RNN序列等长的问题。
Seq2Seq由三部分构成,Encoder编码器,语义编码c,Decoder解码器构成,编码器通过学习将输入序列编码成一个固定大小的向量c,解码器通过对c的学习进行输出。一般来说编码器和解码器都会代表一个RNN,如LSTM或GRU。(也有一般的RNN模型)
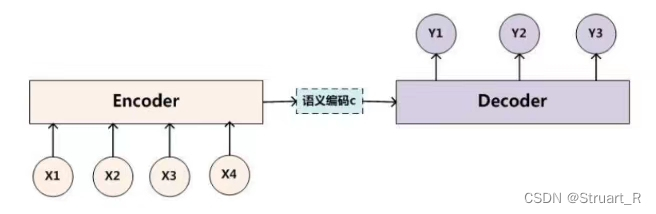
另外另一种方式下,语义编码c将参加解码的每一个过程,而不是只作为初始化参数。
六、自注意力机制
1、注意力机制和自注意力机制
传统注意力机制发生在Target元素和Source元素的所有元素中,权重的计算需要Target来参与。
自注意力机制存在于输入语句内部元素之间或者输出语句内部元素之间,计算权重时也不需要Target来参与。
2、单个输出
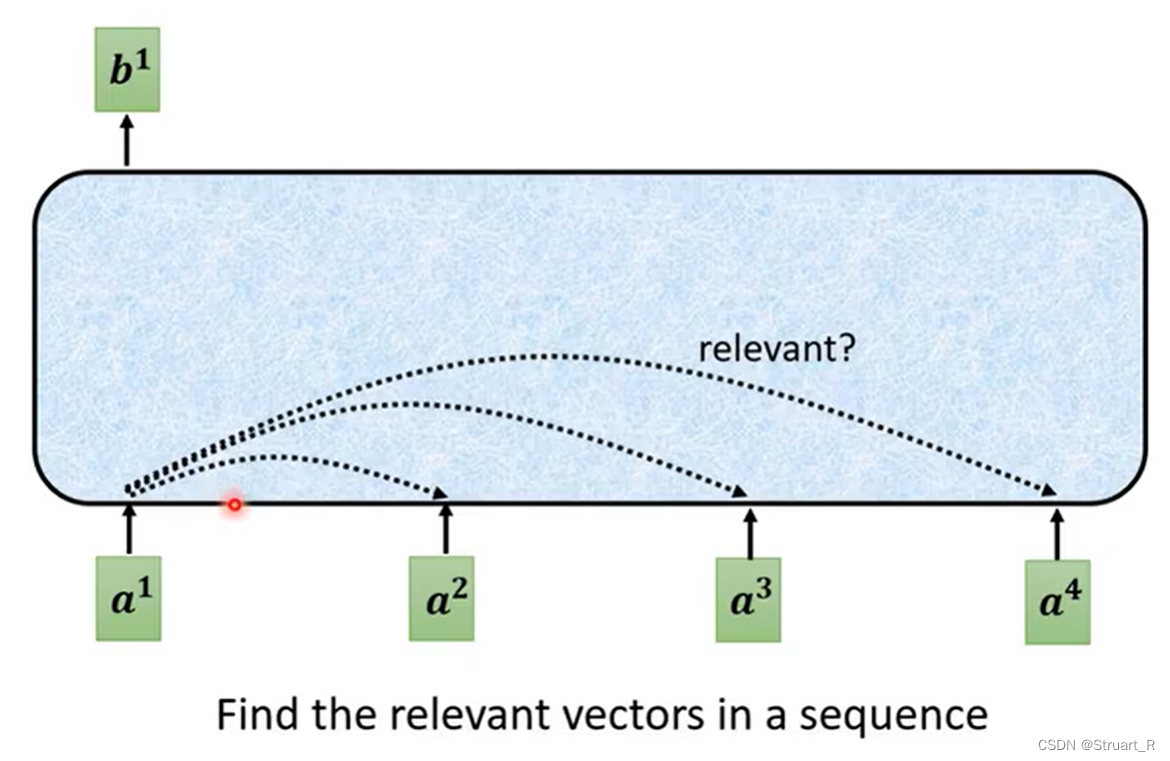
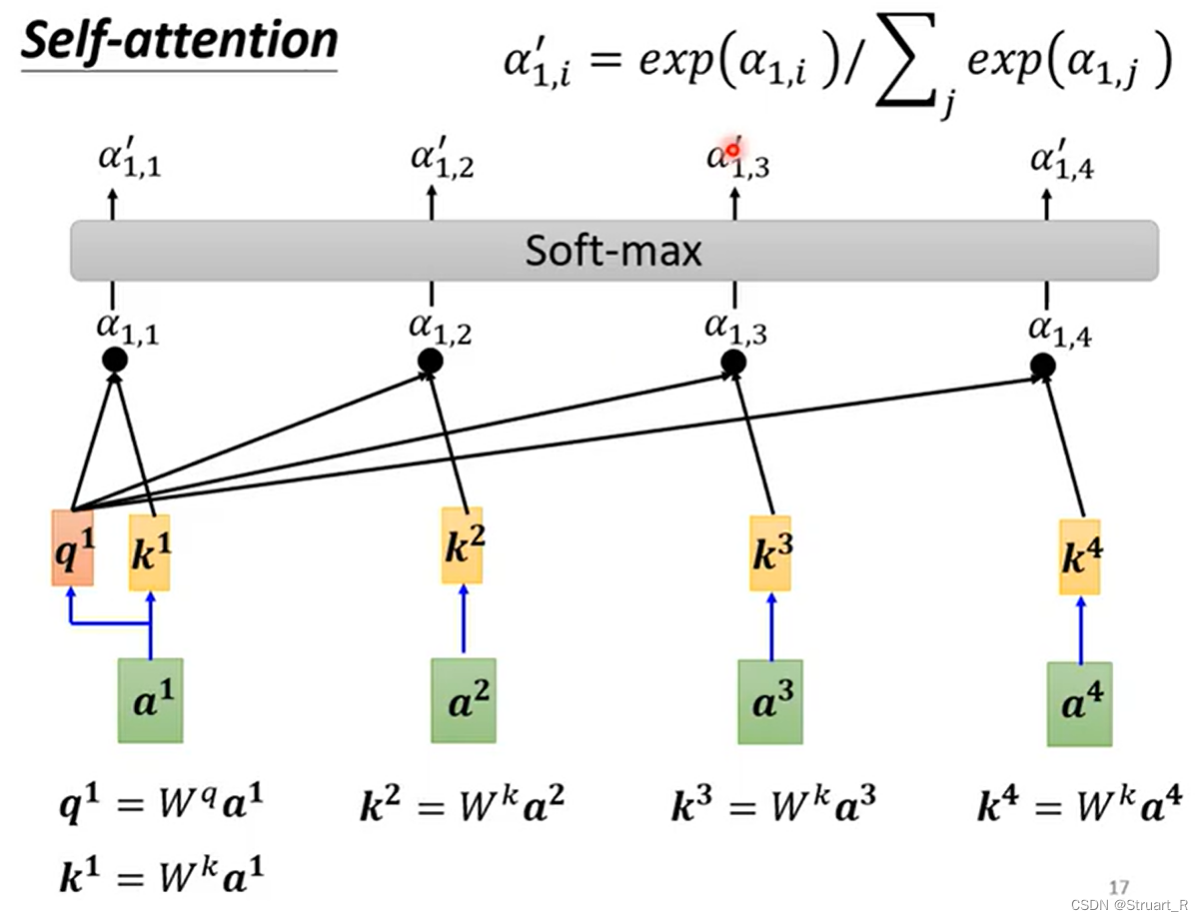
对于每一个输入向量a1,经过self-attention后都会输出一个向量b1,而这个b1是考虑了所有的输入向量a1,a2,...对a1产生的作用才得到的。首先我们将计算两个输入向量之间的α也就是相关性。
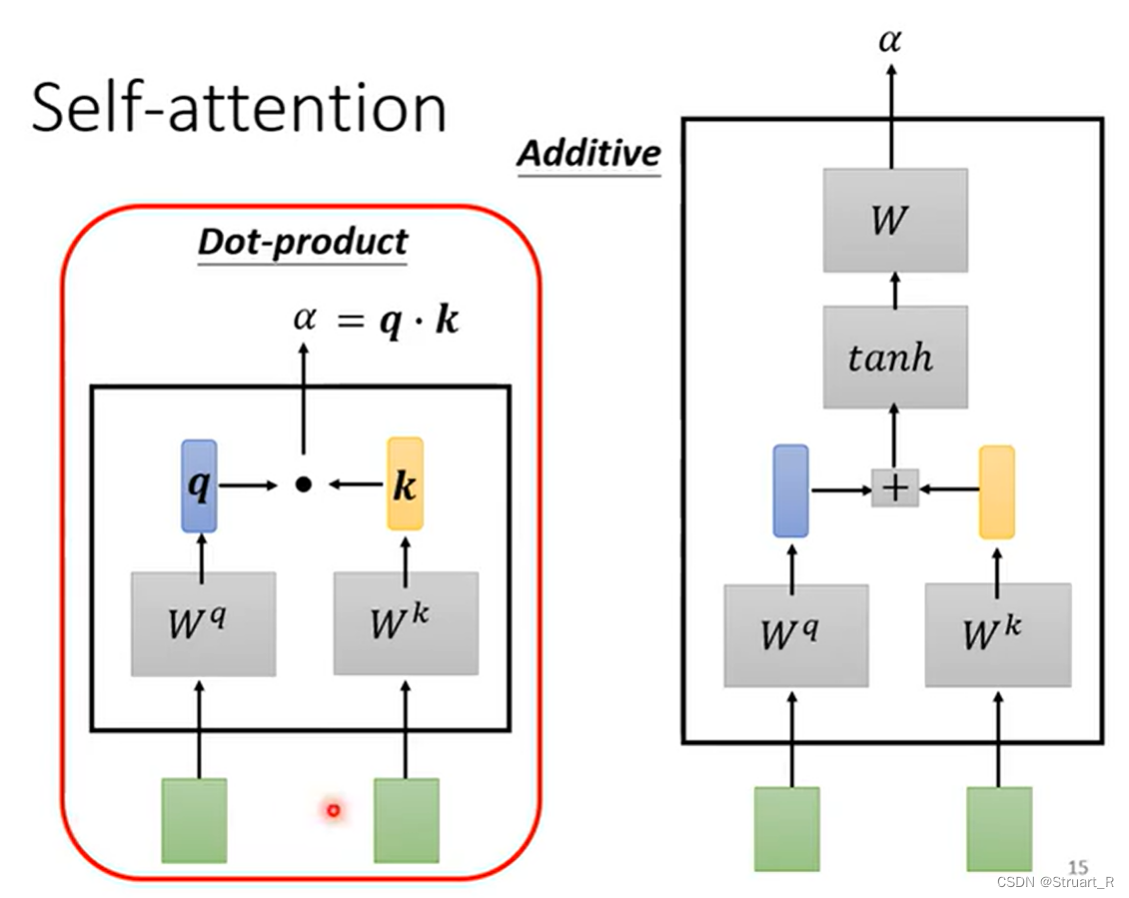
下图中两个绿框,可以代表任意两个输入,比如a1和a2,左侧方法为,a1经过一个矩阵得到q(乘积运算),a2经过一个
矩阵得到k(乘积运算),将q和k做内积运算得到
,也就是图中的α。右侧方法为,a1经过一个
矩阵得到q,a2经过一个
矩阵得到k,将q和k做concat运算后投射到tanh激活函数,在与W矩阵(权重矩阵)做一次乘积得到
。
接下来的操作计算每一个相关性α,下图中为,
,
,
。
几个注意点:都是超参数,是输入进去的,通过与不同的a进行乘积运算得到的
也是不同的。
将,
,
,
放入softmax中进行归一化处理,获得
,
,
,
,softmax的数学公式如下图右上角。
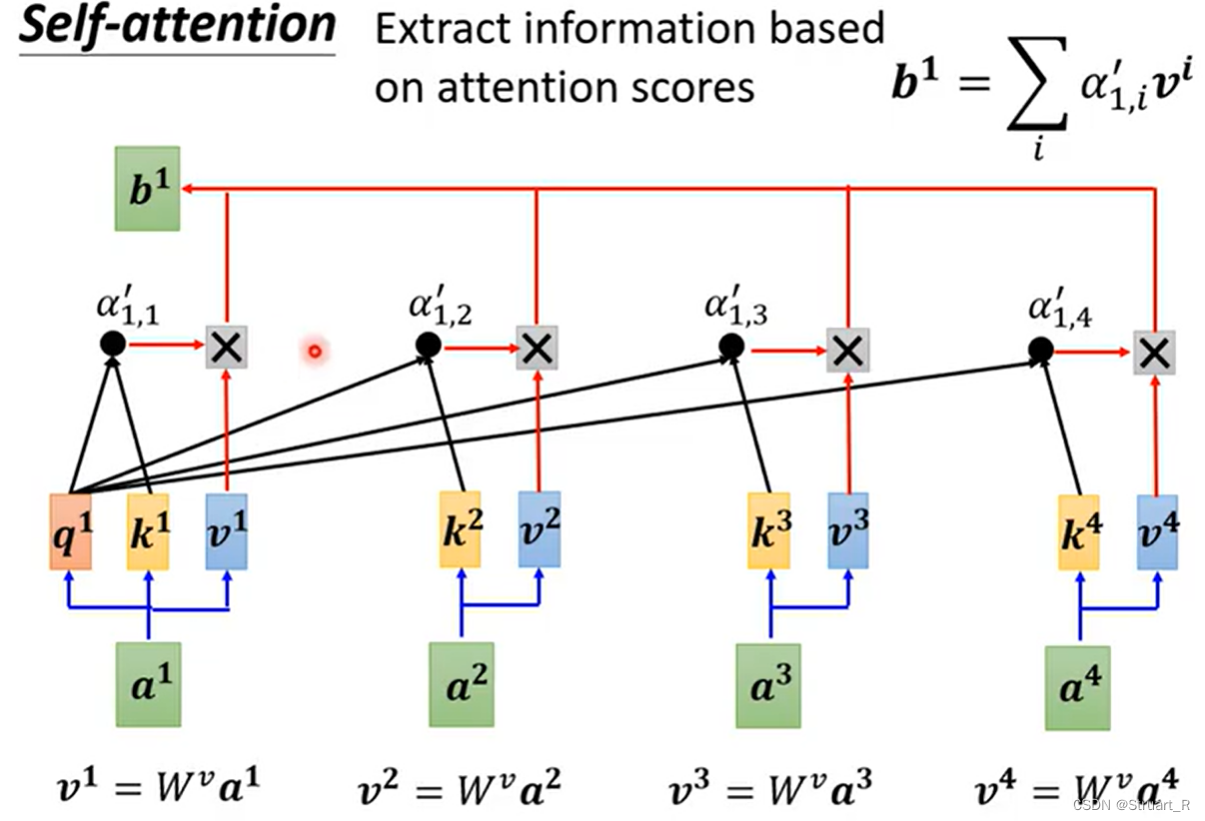
最后将每一个乘以矩阵
得到
,
再与α进行相乘,将每一个相乘后的值相加求和,得到输出的b。b的计算公式如下图的右上角。
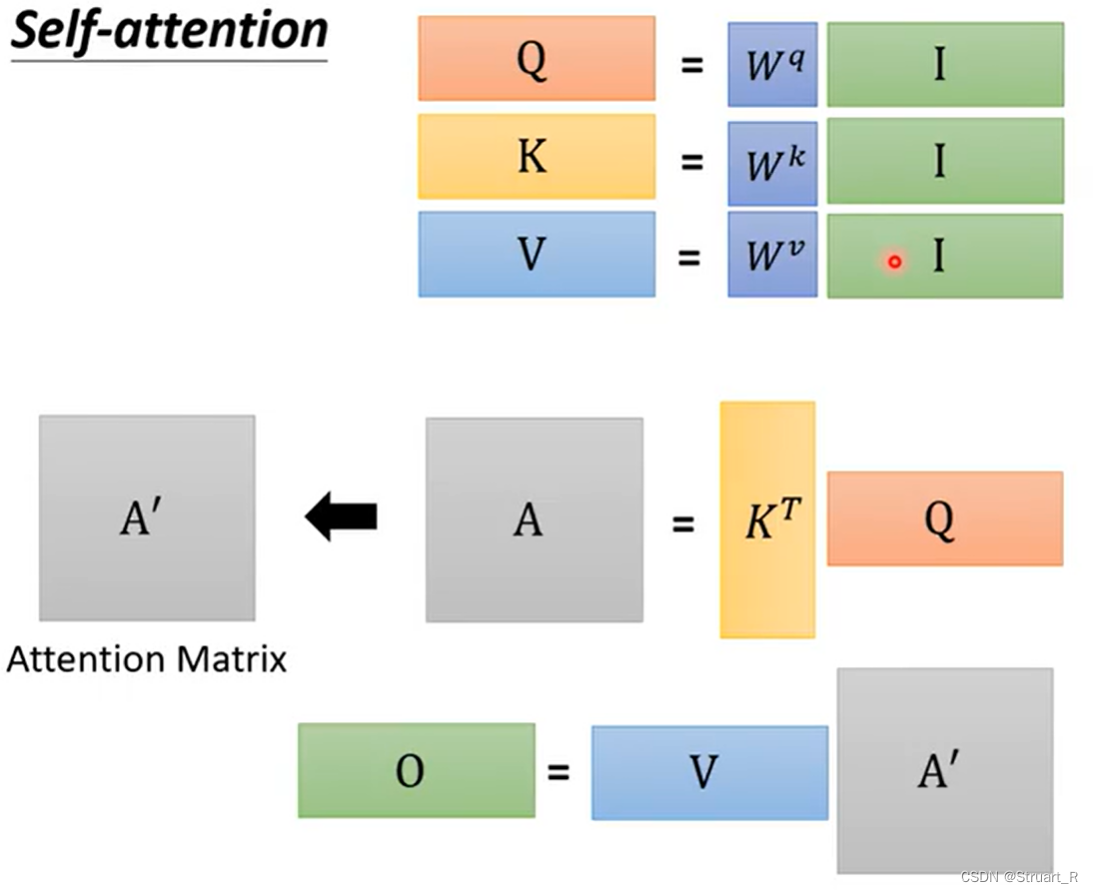
3、矩阵计算
首先可以将一个序列sequence的每一个a都进行concat这样形成了一个矩阵I,分别与进行矩阵乘法,就可以得到相应的q,k,v。
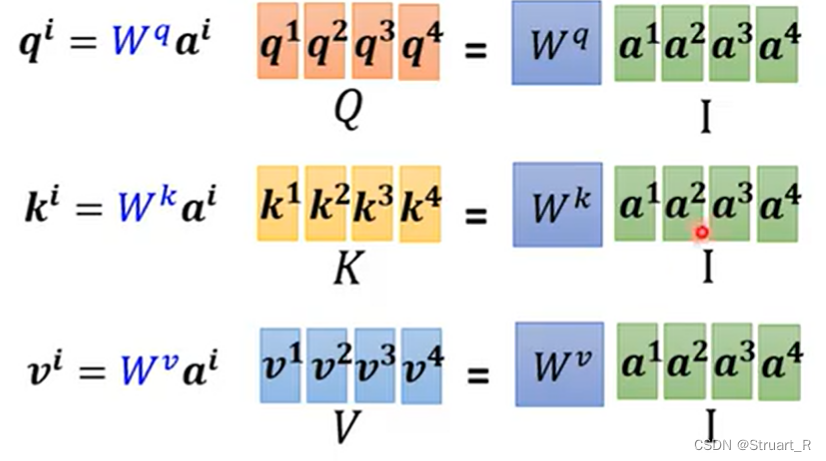
再将生成的每一个q和每一个k分别在x轴和y轴进行concat,形成Q和(K的转置),
与Q进行矩阵乘法,就得到了A(也就是所有α所构成的二维矩阵),经过softmax就得到了A'(α'所构成的二维矩阵)

第三步,将每一个v进行concat操作得到V,将V与A'做矩阵乘法,就得到了O(b进行concat构成的矩阵)
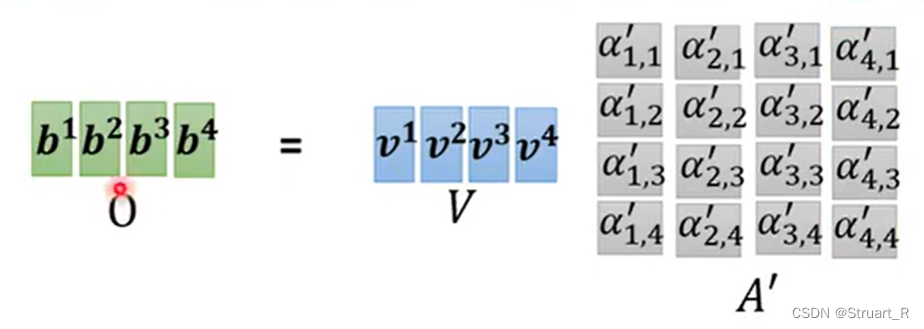
整体来看,就是下图这样的一个矩阵运算操作。
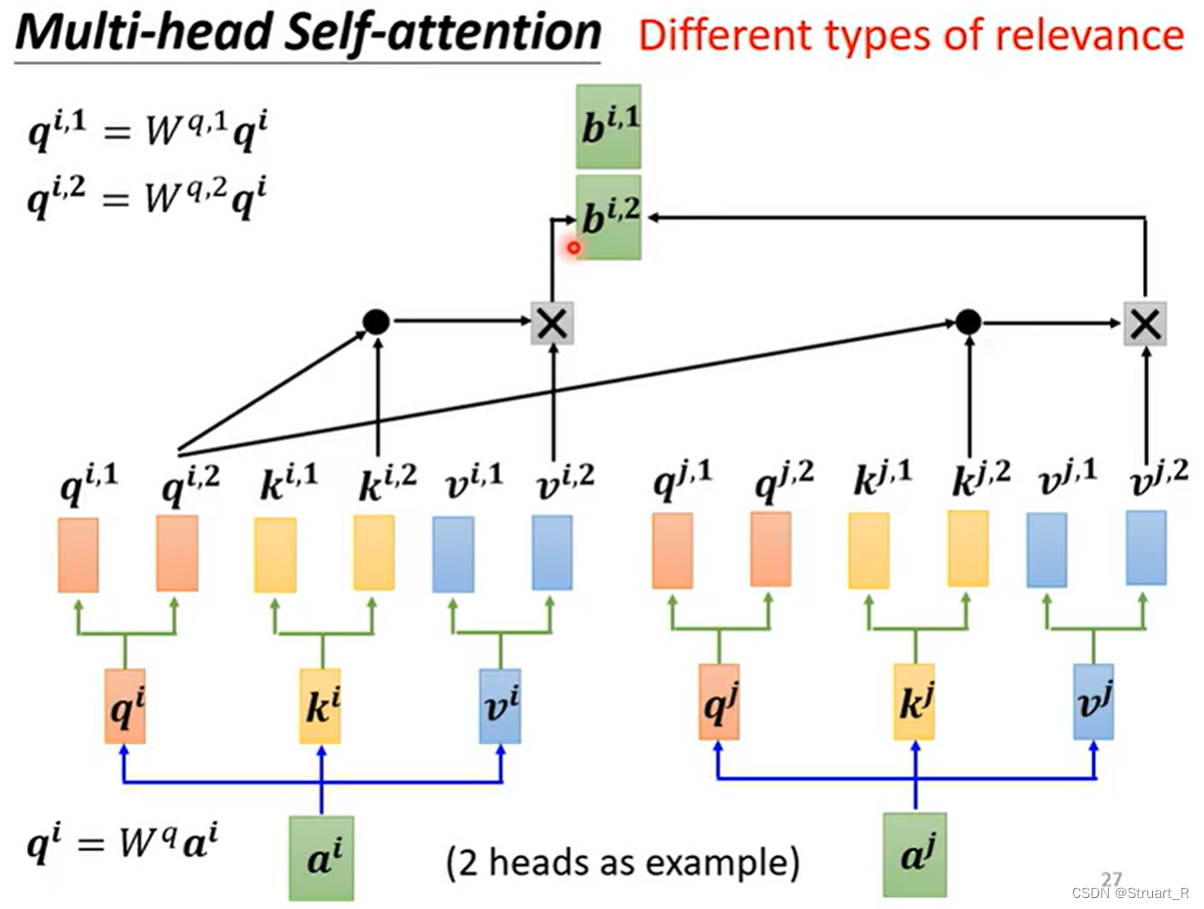
4、multi-head self-attention
多头自注意力机制,由于相关性可能有不同的形式,有不同的定义,所以可以有多个q,k,v来表示多种类型的相关性,也就是在超参数中存在
,
,...。对应的k,v也有多个。
计算每一个的方式如下,最后需要对多个
进行y轴方向的concat,也就是
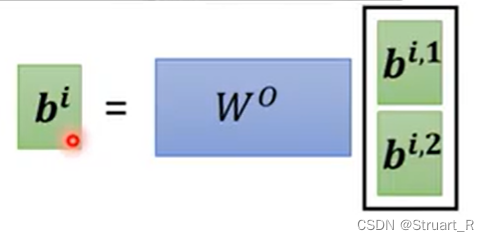
,将
乘上权重矩阵W,得到
5、positional encoding
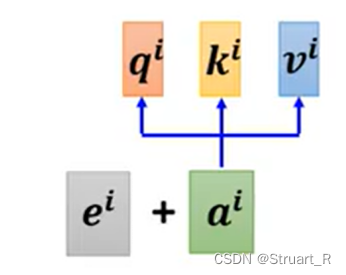
对于训练self-attention时,存在位置信息缺失的问题,位置信息引入到训练数据中,所以我们可以在Self-attention中加入位置信息。
通过设置一个新的positional vector,用表示,对于不同的
处都有一个
体现位置信息,vector的长度时人为规定,也可以通过大量数据训练出适合数据的vector。
参考视频:
37.39、 自注意力机制P37_哔哩哔哩_bilibili
3-注意力机制的作用_哔哩哔哩_bilibili